2020年7月に立ち上がったオンラインコミュニティ「Data Engineering Study」は、これまで12回開催され、累計参加者は8500人に上ります。データ分析基盤を支える人たちが持つ「何をしたらよいのか」という疑問や、「これで合っているのか」という不安に対して、Data Engineering Studyが発信してきた知見や情報をすべて振り返りました。ゆずたそ(@yuztas0)の名前でも知られる、Data Engineering Study モデレーター 横山翔氏が語ります。
2020年7月に立ち上げられたオンラインコミュニティ「Data Engineering Study」は、これまで11回の開催を通し、のべ約1万人の方々にご参加頂いてきました。本セッションは、著名なデータエンジニアであり且つ同コミュニティのモデレーターででもある yuzutas0氏を迎え、立上げからの1年強の全セッションを振り返ります。
※このセッションは事前に収録されたものです
セッションレポート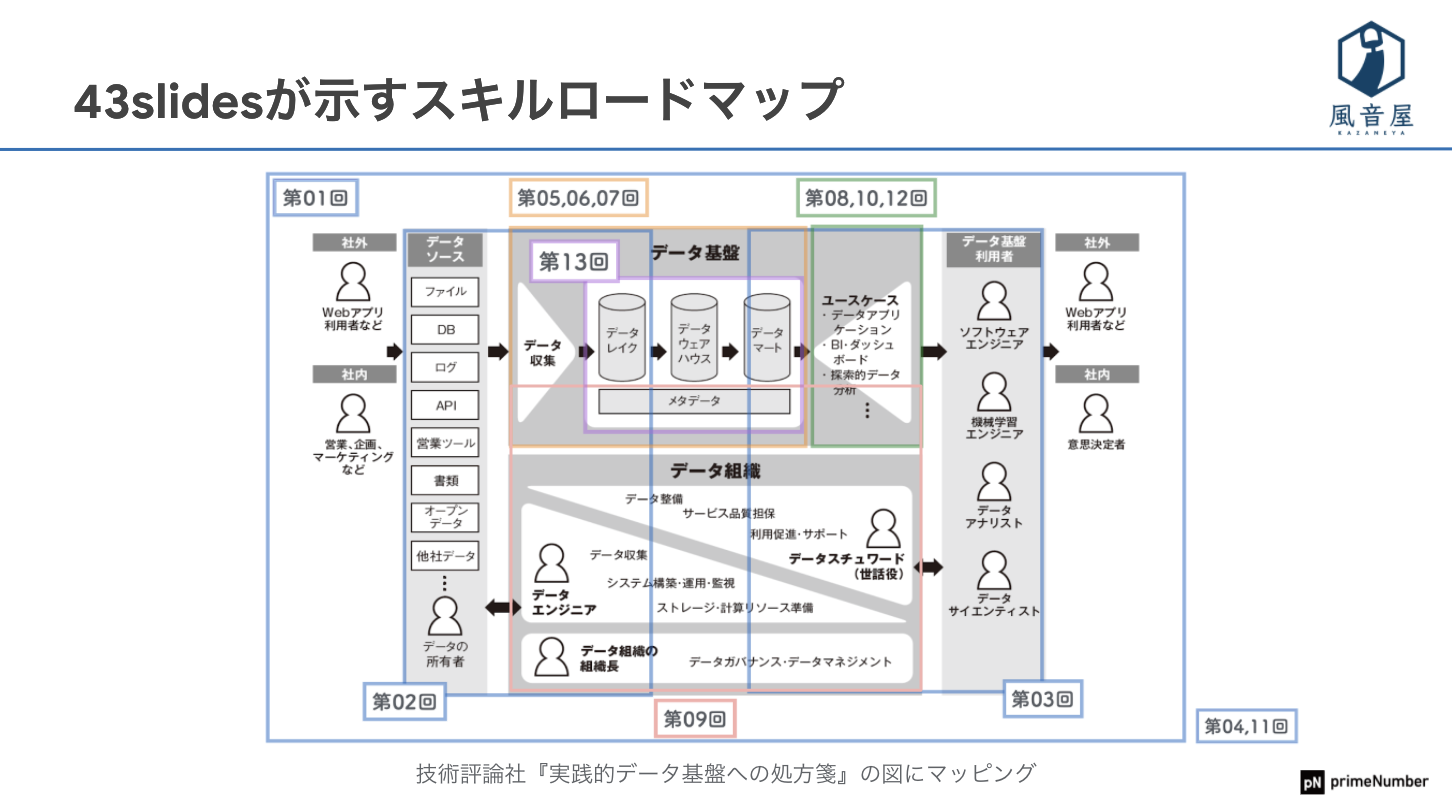

データエンジニアが進むべき道を示す「データ分析基盤の羅針盤」
※投影資料は下記URLで公開されています。
https://speakerdeck.com/yuzutas0/20220224
初心者に向けて実践者の知見や情報を積極的に発信
データ活用は指標のモニタリングをはじめ、ユーザーの利用状況や顧客セグメントの可視化、施策の効果確認など、非常に幅広い用途があります。もちろんシステム化が必要になり、様々な課題もあるため、それを解決できるデータエンジニアの需要が急速に高まっています。
国内最大級のデータエンジニアリング勉強会「Data Engineering Study」の目的は、実践者を招いて、初心者向けに講演してもらうことで、データ分析を支える人材に向けて、情報をより多く流通させることです。これまでのセッションで示されてきたスライドは、「データ分析基盤の羅針盤」と言えるのではないでしょうか。
「Data Engineering Study モデレーターの横山 翔氏は著名なデータエンジニアで、データ分析基盤を2時間で構築した経験を持ち、書籍も出版されています。ゆずたそ(@yuztas0)の名前でもよく知られております」
セッションでは、Data Engineering Studyを時系列に振り返るのではなく、「データアーキテクチャの全体像」から始めて、「データを集める」「データを貯める」「データを加工する」「データを可視化する」「データの利用を促す」「データ組織を運営する」と、テーマごとに話がされました。
「データアーキテクチャの全体像」は第1回で行われ、ETL(抽出・変換・格納)ツール、DWH(データウェアハウス)製品、ワークフローエンジン、BIツールを説明したうえで、ZOZO社やfreee社の事例を紹介しました。
次の「データを集める」は第2回のテーマで、データ収集はデータ分析を行うための1つのフェーズで、ファイルとDB(データベース)からでは収集方法が異なること、IoT(モノのインターネット)デバイスのデータ収集は難しいことが説明されました。
「データ収集は一定期間ごとに処理するバッチとリアルタイムで処理するストリーミングの2つがあり、それぞれ特徴があります。データ量の増加に応じたインフラのスケールなど、運用開始後は様々な工夫が必要です」(横山氏)
データを貯め、加工、可視化して自社のビジネスに生かす
「データを貯める」は第5回、第6回、第7回の3回で紹介されました。第5回では、DWHを選ぶための観点とSnowflakeのよい点を解説しました。
「DWHはツールごとにコストの考え方が異なるため、自社環境に合った製品を選ぶことが重要です。Snowflakeは特定のインフラに依存せず、総合的なデータ活用を支援でき、データの実体と集計処理が疎結合で作られており、フレキシブルに動作します。その利用事例として、毎日2億レコードを処理するColorful Palette社があります」(横山氏)
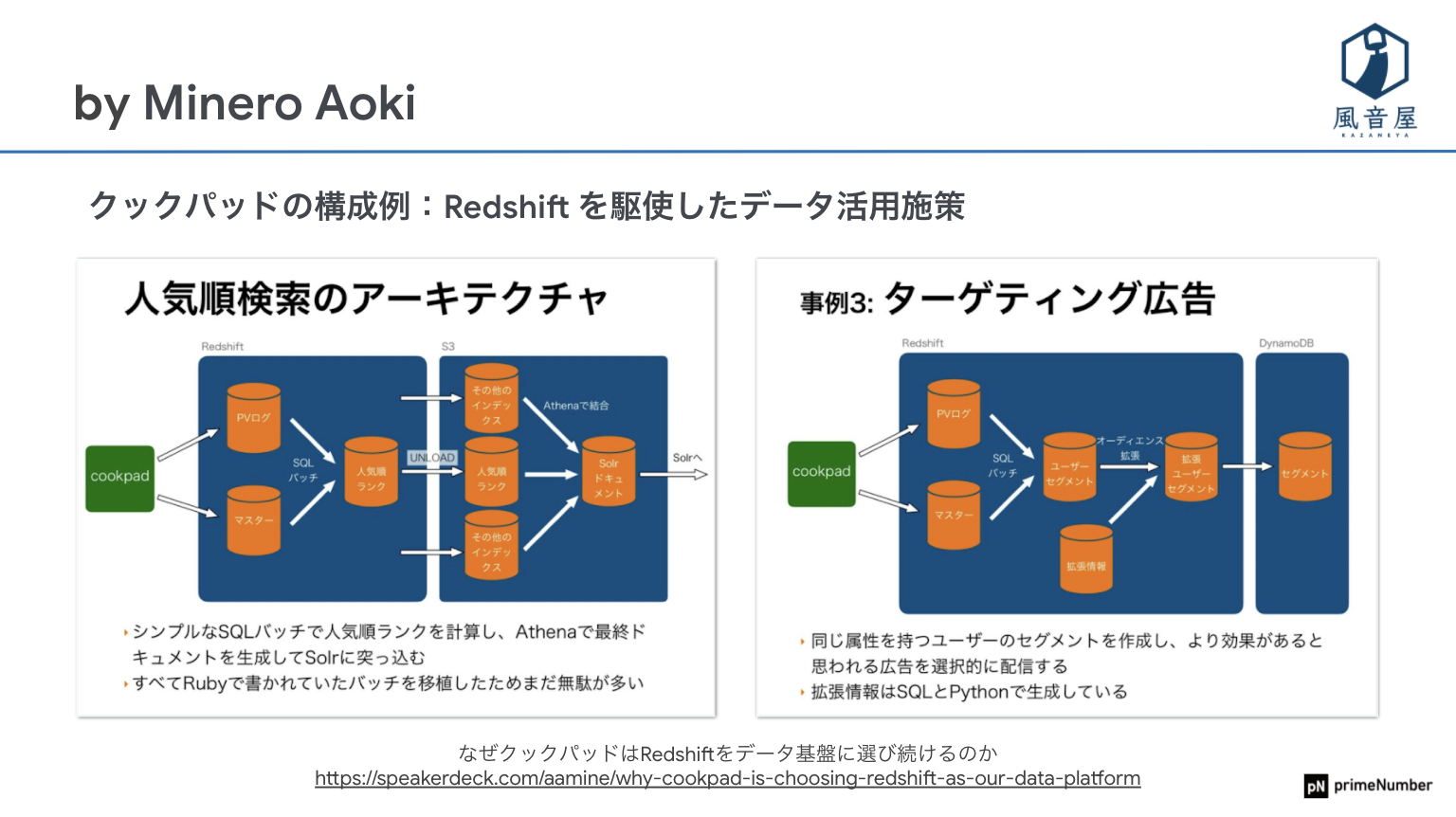
第6回ではGoogle CloudのBigQuery活用例、さらに第7回ではAmazon Redshiftをピックアップしました。Amazon Redshiftは2012年に発表され、ユーザーの意見を反映しながら進化してきています。SQLによる機械学習、他のAWS(Amazon Web Services)へのSQL連携とその逆も可能で、大規模データ処理時には自動でスケールします。利用事例として、クックパッド社の人気順検索のアーキテクチャとターゲティング広告が挙げられました。
「『データを加工する』は2022年4月開催予定の第13回のテーマで、ELT・データモデリングツールと、dbtを利用してモデリングしたUbie社の事例が解説されます。私の書籍では代表的手法としてディメンションモデリングと、trocco®によるELTの実現を紹介しています」(横山氏)
「データを可視化する」は第8回、第10回、第12回のテーマで、第8回はBIツールに特化した勉強会でした。BIツールはそれぞれタイプが違うため、用途や制約に合ったものを選ぶことが重要です。Redashは社内の誰でもデータを見ることができる状態になるのが魅力で、Lookerは集計・定義を共通管理できるため、可視化のアウトプットが増えるほど有益です。ヤプリ社はLookerで、580種のデータを700以上の図表で可視化しています。
第10回は、知名度の高い商用BIツールが紹介されました。マーケティングへの活用が容易なTableau、Googleアカウントで試すことができるGoogleデータポータル、Microsoftアカウントで試すことができるMicrosoft Power BIなどです。
第12回はデータ可視化に関する解説でした。可視化の目的は短時間で必要な情報を得られるようにすることです。グラフによって伝わりやすさが異なるので、目的に合わせたグラフを選び、視覚認知の基本概念「PreAttentive Attribute」「ゲシュタルト法則」を踏まえることが大切です。
大手企業から中堅中小まで、様々な工夫でデータ組織を運営
「データの利用を促す」は、第3回で紹介されました。データ分析基盤を組織に浸透させるには、データ活用を企業戦略や業務フローに組み込むとともに、トップの協力が欠かせません。業務サイクルに組み込むと、自然にデータが使えるようになります。
「MonotaRO(モノタロウ)社では、データ利用に各部門の業務知識が欠かせないため、業務担当者やエンジニアが自分でデータ整備できる仕組みを作られました。エウレカ社では、分析者が中間テーブルを作成し、人事評価につながる体制を構築しています。さらにTableauの社内勉強会を開催し、利用を促しています。、DeNA社では利用促進のために基盤チームを機能別から目的別に組織刷新しています」(横山氏)
「データ組織を運営する」は、第9回で紹介されました。オープンエイト社では登壇者が1人目のデータ人材として入社したため、様々な課題解決のために工夫を重ね、データの生成元となる業務ツールも整備しました。弁護士ドットコム社では社員数100人の段階でデータ部門を立ち上げ、200名になる中で会議体や相談チャンネルを整備しています。
2018年に最初のデータエンジニアが入社したClassi社は社員数200人ですが、データ組織の中でも職種が分かれ、データ民主化の戦略で組織を運営しています。社員数2000人のLINE社は役割に応じて4つの部署に分け、各部署に5つの職種があります。社員が1万5000人のリクルート社では事業ごとにデータ分析基盤が複数存在し、情報交換のために社内勉強会を開始。障害対応を通じて、チームが学びを得るように仕組み化しています。
「最後にETLやワークフローを構築できるSaaS(サービスとしてのソフトウェア)である『trocco®』の構築例を紹介します。trocco®はデータを集める機能が優れていて、日本独自のSaaSからもデータを集められる点が強みです。データの加工ではアナリストがSQLでワークフローを組むことができ、データ利用者が自分でデータの連携、加工が可能です」(横山氏)
「ここまで見てきたように、Data Engineering Studyの足跡は、43枚のスライドに網羅的にまとまっています。これらを通して、ベストプラクティスとしての事例を参照できるため、エンジニアの道しるべになると確信しています。4月には、13回目の勉強会を開催予定ですので、またお会いできるのを楽しみにしています」
登壇者
横山 翔
Data Engineering Study モデレーター
日本におけるDataOpsの第一人者。データエンジニアリング領域に特化した受託開発や技術顧問サービスを提供。コミュニティ活動では、DevelopersSummitのコンテンツ委員やDataEngineeringStudyのモデレーターを担当し、データ基盤やダッシュボードの構築について積極的に情報発信している。当面の目標は100社のデータ活用を支援して各産業の活性化に貢献すること。主な著書に『実践的データ基盤への処方箋』『データマネジメントが30分でわかる本』など。(プロフィール内容は収録時点のものです)

