P!のロゴや「ピップエレキバン」で知られるピップ株式会社様。卸事業・メーカー事業を中心とした非ITビジネスを展開している同社では、エンジニアがほぼ不在であったため、自社の力だけではマーケティング施策や分析業務にデータを活用できない環境でした。
そうした環境で、金澤 岳氏の入社をきっかけにデータ分析基盤の構築がスタート。trocco®をはじめとしたクラウドサービスを活用することで、デジタル施策を強化していくインフラが整いつつあります。
非ITの大企業で、どのようなプロセスでデータ分析基盤の構築が着手されていったのか、また、どのようなポイントで苦労されたのか、プロジェクトの全容についてお話を伺いました。
P!のロゴや「ピップエレキバン」でご存知のピップ株式会社様。非IT企業であり、卸事業・メーカー事業を中心としたビジネスを展開されている同社のデータ活用事例をご紹介します。DXも掛け声先行でエンジニアもいない組織の中、他部署との連携も多岐に渡る大企業のデータ活用をどういったプロセスで着手されていったのか、どういったポイントで苦労されたのか、オンラインとオフラインのデータ統合を視野に入れた今後の展開とビジネスへの意義を含め、赤裸々にお話し頂きます。
セッションレポート








ヒトなし予算なしでも、データ分析基盤は構築できる!大手非IT企業のエンジニア不在組織が考える、データ活用の第一歩
写真は右から
金澤 岳 氏 (ピップ株式会社 商品開発事業本部 広報宣伝部 データサイエンス課)
中山 浩平 (株式会社primeNumber カスタマーサクセス本部 Head of Customer Development)
入社後のファーストミッションは「組織におけるデータ活用環境を整える」こと
SIerや事業会社でのエンジニア業務を経験したのち、フリーランスの期間を挟んで2019年よりピップ株式会社のデータマネジメントチームの立ち上げに携わっている、金澤 岳氏。入社と同時に新設された、メーカー事業部内のデータマネジメントチームに所属し、GCP(Google Cloud Platform)を利用したデータ分析基盤の構築や、trocco®を利用したデータパイプラインの構築・運用といった、データエンジニアリング業務全般を手掛けています。
セッション冒頭で同社のデータ活用環境における入社当時の状況と課題について、金澤氏が振り返りました。
「私が入社した当時、データをマーケティングに活用していきたいが、組織として具体的に何をすればよいのか分からない、という状況でした。
恥ずかしながら、『データ活用=Excelでレポートをたくさん作る』ぐらいの社内認識で、部署ごとにデータソースがバラバラに散らばっており、一元管理ができていなかったのです。本来であれば、業務上のオペレーションと社内の課題を認識した上で、どのようにデータを活用し、いかに課題を解決していくか、というイメージを持つところからスタートします。
しかし弊社の場合、課題を認識する以前にデータ分析基盤がそもそも整っていなかったのです。そこで私にまず与えられたミッションが、『組織におけるデータ活用環境を整える』でした」(金澤氏)
非IT企業、かつエンジニア不在の組織でいかにデータ分析基盤を構築するに至ったのでしょうか。金澤氏がデータ分析基盤を構築するために実施した、以下4つの施策ごとにお話を伺いました。
- データ分析基盤について説明・利用許可
- データ分析基盤の構築
- データの可視化
- trocco®を活用したデータパイプライン構築
エンジニア不在組織に立ちはだかる3つの課題とは
データ分析基盤構築にあたり、社内には大きく3つの課題がありました。
- 経営層への説明が困難
- ITエンジニアの不在
- データ分析基盤構築の予算がない
金澤氏によると、データ分析基盤の構築が必要な理由を経営層へ説明したものの、なかなか意図が伝わらなかったそうです。本来であれば、組織としての課題とあるべき姿を実現するため、どのようにデータを活用していくか、どのような仕組みを構築していくべきかと議論することになりますが、それ以前に「データ活用」という考え方を理解してもらう必要があったといいます。
「すでにECやオンラインサービスを手掛けている会社であれば、Webのアクセスログや広告運用データ、会員情報、その他の基幹系システムのデータがデータ分析基盤に蓄積され、そのデータをBIツールで可視化し、ツールでマーケティング施策を実施する、という流れをイメージすることは難しくありません。
しかし当時の弊社は、データマネジメントに対する考え方を理解することが、とても困難な状況だったのです。そこでデータ分析基盤のあるべき姿をイメージしてもらうことは、いったん保留とし、既存のExcelによるレポーティングを自動化するといった、いわゆる『業務改善の一環』という観点からデータ分析基盤の構築に着手することにしました」(金澤氏)
金澤氏が挙げた2つ目の課題が、ITエンジニアの不在です。同社にはITエンジニアに該当する職種がそもそも存在せず、システムの設計や開発は、要件定義の段階から外部のベンダーに外注していました。そのため、社内リソースのみでインフラやサービスを0から構築した経験がある社員がほとんどいなかったそうです。
人だけでなく、限られた予算も課題だったと金澤氏は語ります。
「私が所属しているデータマネジメントチームは新設されたばかりということもあり、予算の割り当てがほぼなしの状況でした。加えて、データ分析基盤の構築についての理解があまり得られなかったことで、予算がほとんど下りないまま、データ分析基盤の構築を進めることになったのです」(金澤氏)
しかし金澤氏には、クラウドサービスをうまく活用することで、月数千円程度でPoC(Proof of Concept:概念実証)レベルのデータ分析基盤構築や検証、運用した経験があったため、可能な範囲でデータ分析基盤の構築を進めることになりました。
5つのステップで進められたデータ分析基盤構築のプロジェクト
データマネジメントへの社内理解、ITエンジニア、そして予算が充分でないという課題から、ミニマムスタートでデータ分析基盤を構築することになったピップ株式会社。そこでまず金澤氏は、データ分析基盤構築のプロジェクトを5つのステップに分けて実施することにしました。
Step1:クラウドサービスの選定
「お金が掛からないこと、技術的に高いスキルが不要であること、この2点がクラウドサービスを選定する上でのポイントです。候補に上がっていたAWSのRedshiftは運用にだいぶリソースが掛かってしまい、また稼働している分だけ費用が発生するため、PoC向きではないと判断。結果として、GCPのBigQueryを中心としたデータ分析基盤を構築することに決めました」(金澤氏)
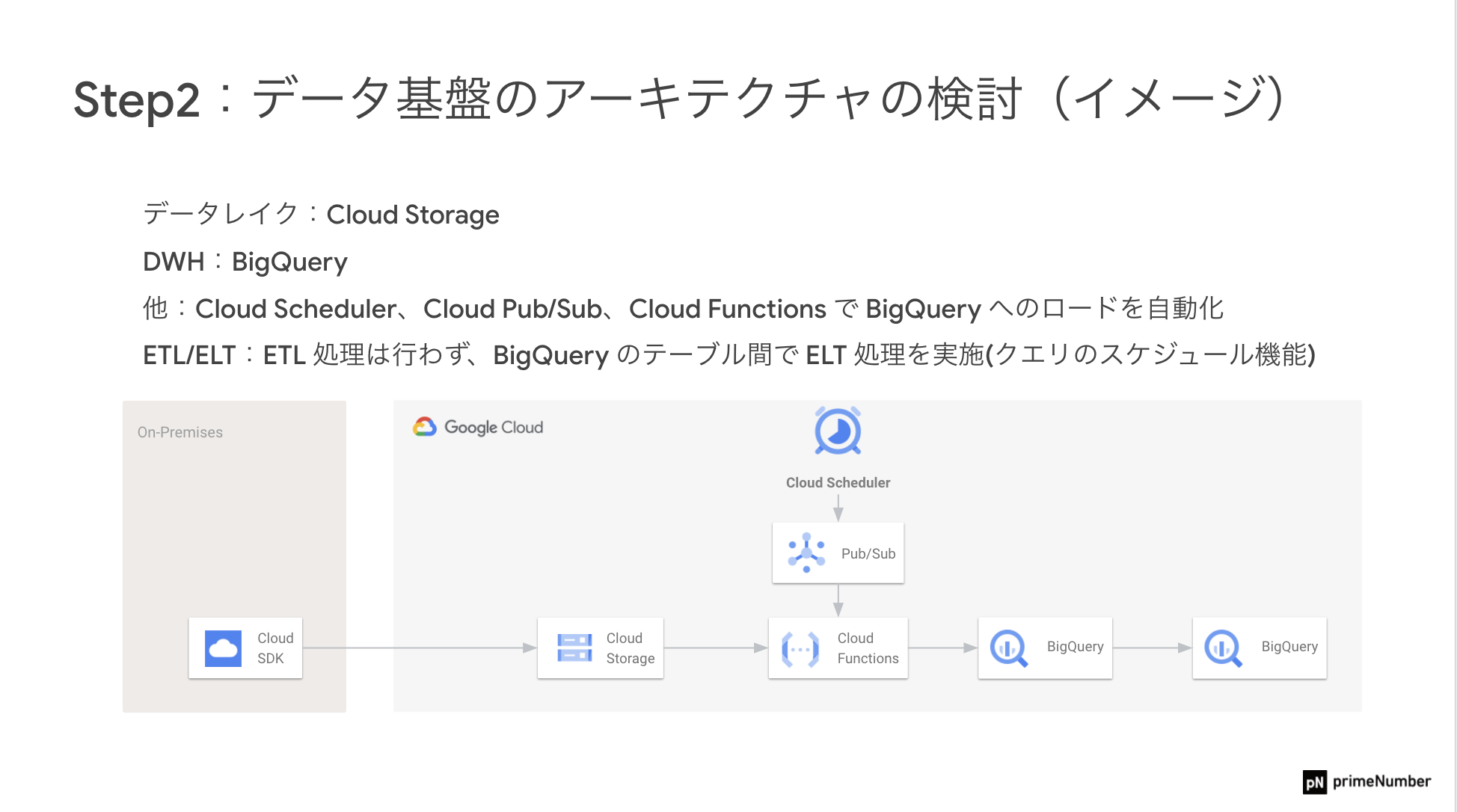
Step2:データ分析基盤のアーキテクチャ検討
人材と予算の関係から、必要最低限のシンプルなデータ構築を目指した金澤氏は以下のようなアーキテクチャを構成しました。
Step3:データレイクの構築
「実際のPoCでは、オンプレミスの社内サーバにあるデータを、ユーティリティコマンドを利用してGCPにアップロードしていきました。毎朝、最新の販売実績データをオンプレミスの社内サーバに格納し、それをシェルスクリプトでCloud Storageに都度アップロードしていく、といったイメージです」(金澤氏)
Step4:DWH(データウェアハウス)の構築
「Cloud Storage上に日々溜まっていく最新のデータを、BigQueryのテーブルに、その都度ロードしていくイメージで構築しています」(金澤氏)
Step5:データパイプラインの設計・構築
「データレイクとDWHの構築が完了したのち、データパイプラインの自動化を進めることになりました。Cloud StorageからBigQueryへのデータ連携には、同じくGCPのサービスであるCloud SchedulerとCloud Functionを活用し、ロード処理の自動化を実現しています。加えて、BigQueryではクエリのスケジュール機能を利用してELT処理を行い、データマート作成まで自動化しました」(金澤氏)
スモールスタートでデータ分析基盤を構築し、データの可視化を実現
データ分析基盤を構築したことでBigQueryのテーブルにデータが自動で連携されるようになり、次のアクションとして「データの可視化」を進めることになりました。BigQuery上のデータをレポートやダッシュボードに落とし込むため、無料のBIツールであるGoogle データポータルを利用しています。LookerやTableauといったBIツールと比べ、機能は限定的ではあるものの、BigQueryとの相性が非常によく、コストが掛からず簡単に利用できることから採用しました。
「弊社ではAmazonで出品している商品の売上実績を閲覧できるダッシュボードを作成しました。
ブランド単位の括りでサマリーされたデータを閲覧できるのですが、ドリルダウン機能を使うことでSKU(Stock keeping Unit:在庫管理上の最小品目)単位でデータを確認できるようになっています。
他にも、ダッシュボードで自動メール配信を設定できるので、週の初めにメールで配信し、最新の状況を確認できる仕組みを作りました」(金澤氏)
trocco®を活用したデータパイプラインの構築と、3つのデータ処理
「GCPによるPoC用の簡易的なデータ分析基盤とダッシュボードの構築に成功したものの、そこで新たな課題が発生しました。取り扱うデータソースが増えたことで、より柔軟性の高いデータパイプラインを構築する必要が出てきたのです。
そこで、本番運用を考慮したETLサービスの比較検討を進めることになりました」(金澤氏)
さまざまな種類があるETLサービスのなかから、同社の状況に合わせてツール選定が実施されました。選定基準は大きく以下の3つです。
- 1人で構築・運用できること
- 開発・運用工数をできるだけ削減できること
- 最低限の費用で運用が可能であること
この3つの要素を満たすサービスを調査・検討した結果、trocco®の導入を決定しました。導入決定後の第一印象について伺いました。
「trocco®は、トライアルのタイミングで初めて触りました。今まで操作したことがある
ETLツールと比べて大変使いやすく、将来的には他のメンバーも扱えるのではないかと感じたのです。
導入に掛かる費用面も、非常に良心的な料金プランだと思います。親会社であるフジモトHD社の情報システム部門もtrocco®の導入に前向きであり、スムーズに導入することができました」(金澤氏)
改めてデータパイプラインを構築するにあたり、trocco®の機能を利用して3つの処理を構築しました。
- 転送ジョブ:ETL処理を実施する機能。様々な分析データをDWHへロードすることが可能。転送元や転送先、対象となるファイルをGUI上から簡単に設定できます。
- データマートジョブ(シンクジョブ):ELT処理を実施し、DWH内にデータマートを作成する機能で、出力先のデータセットやテーブル、更新方法などを簡単に設定できます。また、SQLを記述することで簡単にデータの変換や集計ができ、データマート用のテーブルを作成することも可能です。
- ワークフロー:転送ジョブとデータマートジョブ(シンクジョブ)を複数組み合わせ、ワークフローを作成することができます。スケジューリングも自由に設定し、実行結果に応じてSlackへ通知を飛ばすこともできます。
ダッシュボードを作成し、データを可視化。着実に整えられる、デジタル施策のインフラ
「trocco®の導入にあたっては、primeNumber社のカスタマーサポートにとても助けられました。分からないことをSlackで送ると、すぐに担当の方からレスポンスをいただけています。ただ早いだけでなく、丁寧に対応していただけたことも、他のエンジニアがほぼ不在の弊社にとって、とてもありがたかった要素です」(金澤氏)
エンジニア不在のスモールスタートから試行錯誤を重ね、レポーティングの自動化やデータの可視化を目的にtrocco®でデータ分析基盤を構築したピップ株式会社。現時点で具体的にどのような成果が得られたのでしょうか。
「Amazon上の売上実績の可視化をはじめ、一部のデータではダッシュボード作成や自動配信の運用がスタートしている状態です。また、2021年にリニューアルした自社ECの会員情報や購入履歴といったデータをもとに、CDP(Customer Data Platform)の構築も進めています。
社内でのデジタル施策を強化していくためのインフラが、少しずつ整ってきたと感じていますね」(金澤氏)
スモールスタートで今できることからデータ分析基盤を整えていくべき
金澤氏は今回の取り組みを通して、組織としてデータ活用の戦略を描くことは重要ではあるものの、スモールスタートで今できることから少しずつデータ分析基盤を整えていく方法もぜひ検討すべきだと話します。加えて、戦略よりもデジタル施策を運用するために必要な組織づくりや採用戦略、社員のITリテラシー向上といった組織面にも力を入れるべきとアドバイスしました。
「講演のタイトルに『エンジニア不在組織』と書きましたが、やはりエンジニアはいたほうがよいと思います。データ分析基盤の構築だけでなく、MAツールやSaaSとのデータ連携を行う上で、技術面のさまざまな課題やハードルを乗り越えていかなければなりません。
また、今回の取り組みを通して、データ分析基盤の構築自体には意外とコストは掛からないのだと気付かされました。特にサーバレスのクラウドサービスを組み合わせることで、PoCレベルであれば月1,000円前後でプロトタイプを組めると思います。
構築自体にはコストは掛からないものの、ELT処理をはじめ、データパイプラインの運用はけっこう大変です。積極的に工数を削減していくためにも、trocco®のような便利ツールは、ぜひ積極的に導入すべきだと思います」と講演を締めくくった。
登壇者
金澤 岳 氏
ピップ株式会社
商品開発事業本部 広報宣伝部データサイエンス課
金融系SIer、会計事務所、事業会社IT(業務系システム運用(会計・人事給与)・DWH運用)、フリーランスエンジニアを経て現職へ。
現職ではデータエンジニア関連業務としてGoogle Cloudを利用したデータ基盤構築、troccoによるデータパイプライン構築を行うとともに、デジタルマーケティング業務のサポートとしてWEBアクセスログ解析、CRM・MAツールの環境構築・運用を担当。
現職ではデータエンジニア関連業務としてGoogle Cloudを利用したデータ基盤構築、troccoによるデータパイプライン構築を行うとともに、デジタルマーケティング業務のサポートとしてWEBアクセスログ解析、CRM・MAツールの環境構築・運用を担当。
中山 浩平
株式会社primeNumber
カスタマーサクセス本部 Head of Customer Development
エンジニアとしてキャリアをスタート、2012年以降はスタートアップベンチャー、大手クラウドベンダーでの経験を経て、2020年よりprimeNumberへ入社。日本以外にも東南アジアでの新規開拓営業を中心に、SI案件、SaaSなど様々な商材に携わり、お客様のご支援を実施。現在はプリセールス領域にて自社サービスtroccoの拡販を主導している。
企業情報
ピップ株式会社
https://www.pipjapan.co.jp/
設立:1908年(明治41年)
資本金:2億7,000万円
従業員数:625名(2021年10月)
事業内容:医療衛生用品、健康食品、ベビー用品、ヘルスケア用品、日用雑貨、医薬品、医薬部外品、医療機器などの卸販売。ピップエレキバン、ピップマグネループ、スリムウォークなどの自社開発商品の製造・販売






